vLLM Semantic Router v0.2 Athena: ClawOS, Model Refresh, and the System Brain
Since v0.1 Iris, vLLM Semantic Router has made a large jump. In one release cycle, the project rebuilt its model stack, expanded routing into safety, semantic caching, memory, retrieval, and long-context signal handling, and started pushing toward a broader ambition: turning semantic routing into the system brain for mixture-of-models and multi-agent deployments.
Athena is where that shift becomes visible. v0.2 ships a complete model refresh and a much stronger routing runtime, but one of its boldest new bets is ClawOS: an experimental operating layer where Semantic Router can orchestrate multiple OpenClaw systems through routing, memory, safety, and chat-driven team management. If Iris established the bridge between users and models, Athena starts turning that bridge into an operating surface for model teams.
Why Athena?
In Greek mythology, Athena represents wisdom, strategy, and disciplined craft. That symbolism fits this release precisely. v0.2 is not just about routing requests faster or adding more plugins. It is about making semantic routing more strategic: learning which model to choose, coordinating teams of OpenClaw workers, remembering what matters across turns, exposing decisions through better tooling, and turning a powerful runtime into something teams can actually operate.

What's New in v0.2 Athena?
1. A Complete Model Refresh Rebuilds the MoM Foundation
The most consequential change in Athena sits below the UI and below the routing DSL: the model stack was rebuilt.
Athena now centers on a new long-context multilingual base, mmbert-embed-32k-2d-matryoshka, and a new classifier family collected under mom-multilingual-class. In practice, that means the router's embedding, intent, jailbreak, PII, feedback, fact-check, and related classifier surfaces are moving onto a shared mmBERT-derived foundation instead of a more fragmented base-model story. Just as importantly, that refreshed family now lines up with the same ONNX + Flash Attention acceleration path.
Athena also introduces multi-modal-embed-small, a standalone embedding model that puts text, images, and audio into one shared 384-dimensional space. It is designed for true cross-modal retrieval, so the system can search images with text, find audio with text descriptions, and align content across all three modalities. Just as importantly, it keeps the deployment story simple: it can be loaded with transformers and torch without custom runtime dependencies.
This new model layer brings three changes that matter immediately:
- Multi-Modal Embed Small gives Athena a compact cross-modal primitive at ~120M parameters, with a shared 384d space, strong image-text alignment, 2D Matryoshka controls, sub-100ms inference targets, and reported Audio-Text Retrieval R@1 = 36.4%
- mmBERT-Embed-32K-2D-Matryoshka gives the router a production-ready multilingual long-context backbone: 32K context, 1800+ languages, 307M parameters, STS 80.5, 768d -> 256d truncation with ~99% quality retention, and 22L -> 6L early exit for roughly 3.3x speedups
- the mom-multilingual-class collection turns that backbone into a coherent classifier family, so long-context multilingual routing and safety tasks can share the same base-model assumptions and the same ONNX acceleration path
At the time of this release, the mom-multilingual-class collection spans five core routing and safety tasks, each exposed in both merged and LoRA form:
| Task | Merged model | LoRA model |
|---|---|---|
| Intent | mmbert32k-intent-classifier-merged | mmbert32k-intent-classifier-lora |
| Jailbreak | mmbert32k-jailbreak-detector-merged | mmbert32k-jailbreak-detector-lora |
| PII | mmbert32k-pii-detector-merged | mmbert32k-pii-detector-lora |
| Fact-check | mmbert32k-factcheck-classifier-merged | mmbert32k-factcheck-classifier-lora |
| Feedback | mmbert32k-feedback-detector-merged | mmbert32k-feedback-detector-lora |
That classifier collection is only one part of the refresh. Athena also pairs it with a new embedding backbone, a new multimodal embedding model, and a much stronger production acceleration path. At a higher level, the model refresh in v0.2 looks like this:
| New foundation | What Athena changes |
|---|---|
multi-modal-embed-small | Unified text-image-audio embeddings in one 384d semantic space |
mmbert-embed-32k-2d-matryoshka | 32K context, 1800+ languages, 2D Matryoshka runtime controls |
| ONNX + CK Flash Attention | The refreshed model stack becomes materially faster in production, not just newer on paper |
This matters because Athena's model refresh is also a runtime refresh. The ONNX path, ROCm support, and CK Flash Attention work turn the new foundation into a deployable latency story.
In our three-way benchmark on AMD Instinct MI300X with the real router path Envoy (:8801) -> ext_proc -> SR (:50051), the end-to-end latency profile changed dramatically:
| Request size | ONNX + GPU avg | ONNX + CPU avg | Candle + CPU avg |
|---|---|---|---|
| ~500 tokens | 22 ms | 853 ms | 1053 ms |
| ~2000 tokens | 31 ms | 1814 ms | 1805 ms |
| ~8000 tokens | 128 ms | 4796 ms | 1830 ms |
At the signal level, the gains are even clearer. For domain extraction, ONNX+GPU ran at 10.2 ms on ~500 tokens, 16.3 ms on ~2000 tokens, and 36.1 ms on ~8000 tokens, versus 630.4 / 833.3 / 743.9 ms on ONNX+CPU and 849.0 / 1304.9 / 1311.5 ms on Candle+CPU. For PII extraction, ONNX+GPU reached 8.4 ms, 19.0 ms, and 118.8 ms at those same lengths, versus 729.5 / 1781.8 / 4783.9 ms on ONNX+CPU and 854.2 / 1299.8 / 1327.8 ms on Candle+CPU.
The Flash Attention story is just as important. With three classifiers loaded concurrently on MI300X, the old SDPA path hit a memory wall, while the new CK Flash Attention path kept scaling:
| Sequence length | SDPA | CK Flash Attention | Result |
|---|---|---|---|
| 4096 | 167 ms | 51 ms | 3.3x faster |
| 8192 | OOM | 105 ms | SDPA fails, FA works |
| 16384 | OOM | 259 ms | FA works at 16K |
| 32768 | OOM | 756 ms | FA reaches full 32K |
What makes this especially important is how FA is supported. Under onnx-binding/ort-ck-flash-attn, Athena adds a standalone ONNX Runtime custom-op library that registers com.ck::CKFlashAttention on ROCm and calls AMD Composable Kernel tiled FMHA kernels directly. A graph-rewrite step then rewrites mmBERT ONNX graphs layer by layer, replacing the dense SDPA attention subgraph with a single CK Flash Attention node.
That rewrite is where much of the systems gain comes from. Instead of materializing a dense [1, 1, S, S] attention mask, the rewritten graph derives a lightweight [B, 1, 1, S] padding bias from attention_mask and passes sliding-window settings directly into the kernel. Local-attention layers use CK's built-in window parameters, while global-attention layers switch back to full attention with unlimited windows. In other words, Athena's FA path is not just a backend toggle. It is a model-aware ONNX rewrite plus a custom ROCm kernel path built specifically for long-context mmBERT inference.
Under heavier load, CK Flash Attention still completed 20 concurrent 32K-token requests at 9872 ms median / 14862 ms p95 with zero OOMs, while preserving identical classification outcomes across the validation queries. That is why the model reset belongs at the front of this release: Athena did not just add features around the router. It changed the computational foundation underneath it.
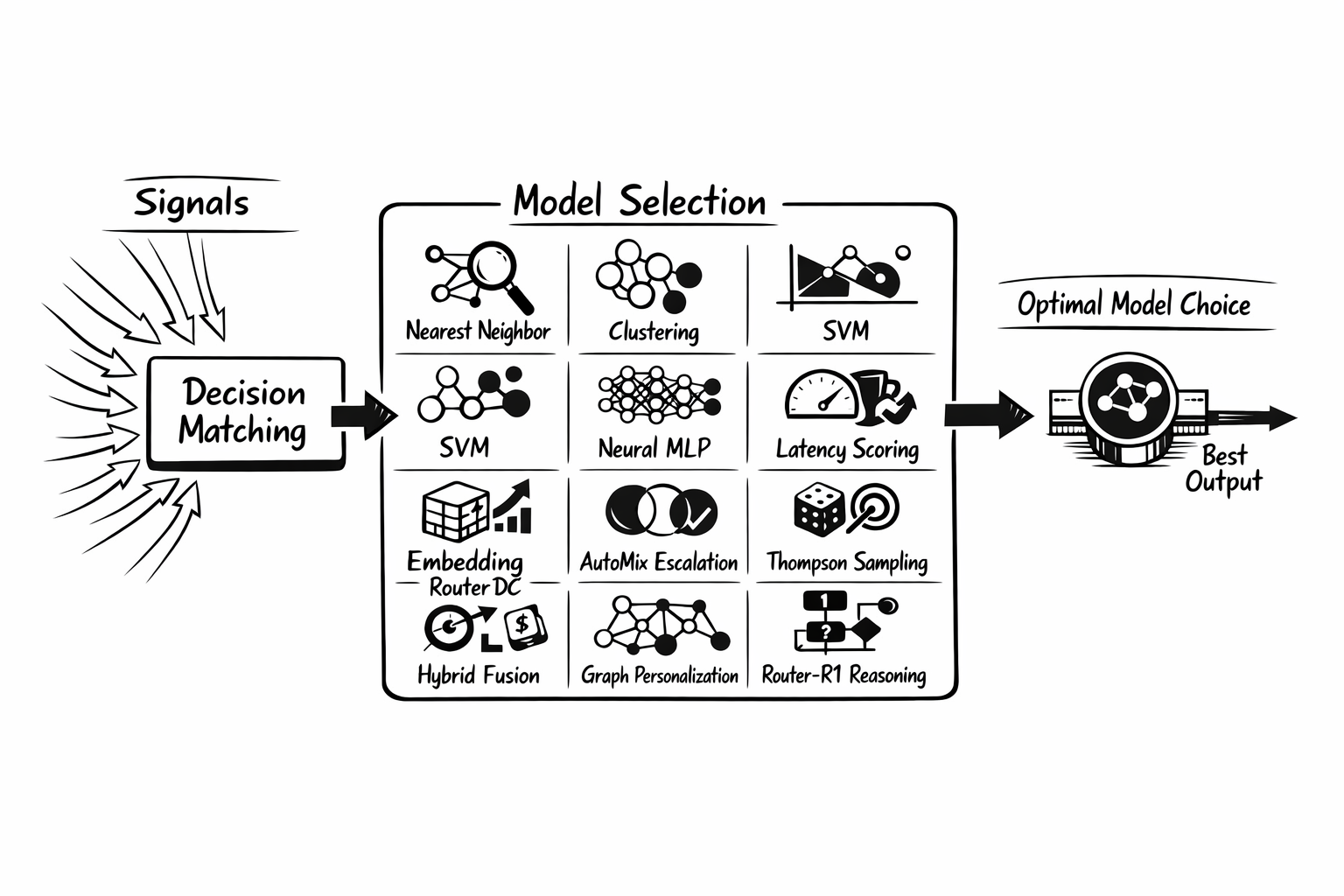
2. Model Selection Becomes a First-Class Routing Primitive
The biggest leap in Athena is that model selection is no longer just a roadmap item. It is now a concrete part of the system, spanning both trainable ML selectors and advanced runtime selection strategies.
Just as importantly, Athena makes its position in the routing pipeline explicit. Model selection does not replace signal extraction or decision matching. The system first extracts signals, then evaluates decisions, and only after a decision matches does a per-decision algorithm choose among that decision's modelRefs. In other words, model selection becomes the last strategic step between "this request belongs to this decision" and "this exact model should serve it."
This matters because modern LLM systems do not just need to decide whether a request belongs to a route. They need to decide which model should handle it under changing tradeoffs in quality, latency, cost, and specialization. Athena makes that strategic layer visible and programmable.
| Family | Method | What it does |
|---|---|---|
| ML-based | KNN | Finds similar historical queries and lets nearby examples vote for the best model. |
| ML-based | KMeans | Clusters requests and assigns models based on cluster-level quality and efficiency patterns. |
| ML-based | SVM | Learns nonlinear decision boundaries between model preferences using an RBF classifier. |
| ML-based | MLP | Uses a neural router to predict the best model from embeddings, with efficient inference through Candle. |
| Advanced | Static | Uses a fixed default model when predictability matters more than adaptation. |
| Advanced | Latency-Aware | Selects the fastest candidate from TPOT and TTFT percentile data when latency budgets dominate. |
| Advanced | Elo | Learns from user feedback and pairwise preferences using Bradley-Terry style rating updates. |
| Advanced | RouterDC | Matches queries to model descriptions with dual-contrastive embedding similarity. |
| Advanced | AutoMix | Starts with cheaper models and escalates based on self-verification to balance cost and quality. |
| Advanced | Hybrid | Blends multiple methods such as quality, similarity, and cost with configurable weights. |
| Advanced | Thompson Sampling | Balances exploration and exploitation online so routing can keep learning while serving production traffic. |
| Advanced | GMTRouter | Personalizes model choice from multi-turn interaction history with graph-based routing. |
| Advanced | Router-R1 | Uses an external router model to reason about the request before choosing a downstream model. |
Athena also adds the operational layer around these algorithms: setup wizard support for ML training and config generation, CLI and runtime integration, metrics, E2E coverage, and Elo feedback surfaces in the dashboard for human-in-the-loop refinement.
3. ClawOS Turns Semantic Router Into an Operating Layer for OpenClaw
One of Athena's boldest new bets is ClawOS: an experimental operating layer that lets Semantic Router orchestrate multiple OpenClaw systems.
Inside the repo, the distinction is straightforward:
- OpenClaw is the underlying agent platform
- ClawOS is the orchestration and operating experience Athena builds on top of it inside Semantic Router
What matters in v0.2 is that this is already tangible, not just conceptual. Through built-in MCP tools and room-style chat workflows, users can use natural-language conversations to spin up different OpenClaw teams and workers, coordinate them in real time inside shared rooms, and observe the runtime state of the whole multi-claw system from one place.
The point of this feature is not just to add another dashboard page. It is to explore how Semantic Router can power multiple OpenClaw systems with routing intelligence, memory, safety, and team control all connected in one surface.
The dashboard highlights the capabilities we want to bring into that setup:
- Intelligent Routing for cost-quality model selection
- Safety Guardrails against jailbreaks, PII leakage, and hallucination risk
- Hierarchical Memory Storage for long-horizon, multi-step execution
- Knowledge Sharing across agents
- Isolation & Team Management for multi-agent operations in one shared orchestration layer
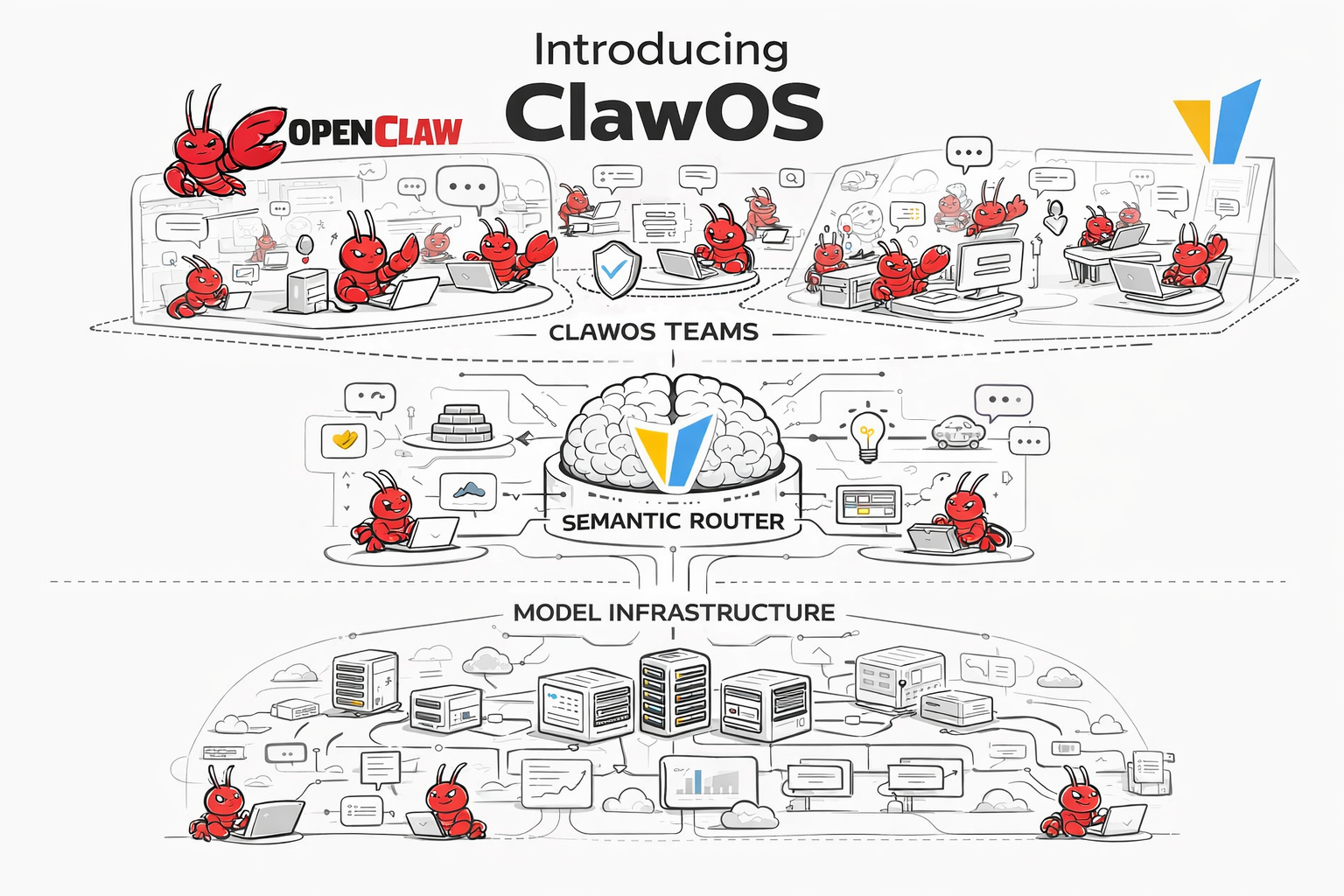
Athena adds the first set of product surfaces that make this experiment tangible:
- natural-language MCP control so users can spin up and manage different OpenClaw teams and workers directly through chat
- team support with explicit leader-and-worker composition
- shared room chat so teams can talk, coordinate, and execute inside the same room in real time
- leader-and-worker collaboration so leader claws can coordinate worker claws as one operating unit
- worker provisioning directly from the dashboard
- runtime health, team composition, and status views
- readonly room chat for safer demos and public-beta style deployments
- shared runtime support so Claw workers can live alongside the router in the same operational environment
ClawOS is important not because it is a finished platform, but because it is an early, experimental answer to a bigger question: what happens when semantic routing does not just choose a model, but powers a whole multi-agent operating layer built on OpenClaw?
4. Memory, RAG, and Response State Move Into the Core Runtime
Athena also makes state a core concern instead of a side feature.
On the memory side, the release adds Agentic Memory with Milvus storage, hybrid memory search, memory scoring, Llama Stack vector backends, and memory metrics for monitoring and alerting. On the response side, Athena deepens OpenAI Responses API support with Redis persistence, conversation chaining coverage, and stronger integration tests. On the debugging side, Athena introduces Router Replay with pluggable storage backends, per-decision isolation, and dashboard visualization.
That hybrid search work deserves to be called out more explicitly. Athena turns retrieval into a fused search problem rather than a vector-only lookup. In the vector store and memory stack, the router can now combine vector similarity, BM25, and n-gram text matching, with support for both weighted fusion and RRF. The in-memory backend can run hybrid search natively, while Milvus-style backends can use a broader candidate pull plus hybrid reranking on top of vector results.
This matters for the same reason BM25 and n-gram matter in the signal layer: retrieval becomes less brittle. Semantic similarity is still the backbone, but exact terms, sparse relevance, and typo-tolerant overlap can now move the final ranking. Athena also carries this into end-to-end RAG coverage, including weighted hybrid search, RRF mode, and tunable BM25 / n-gram parameters in the vector-store test path.
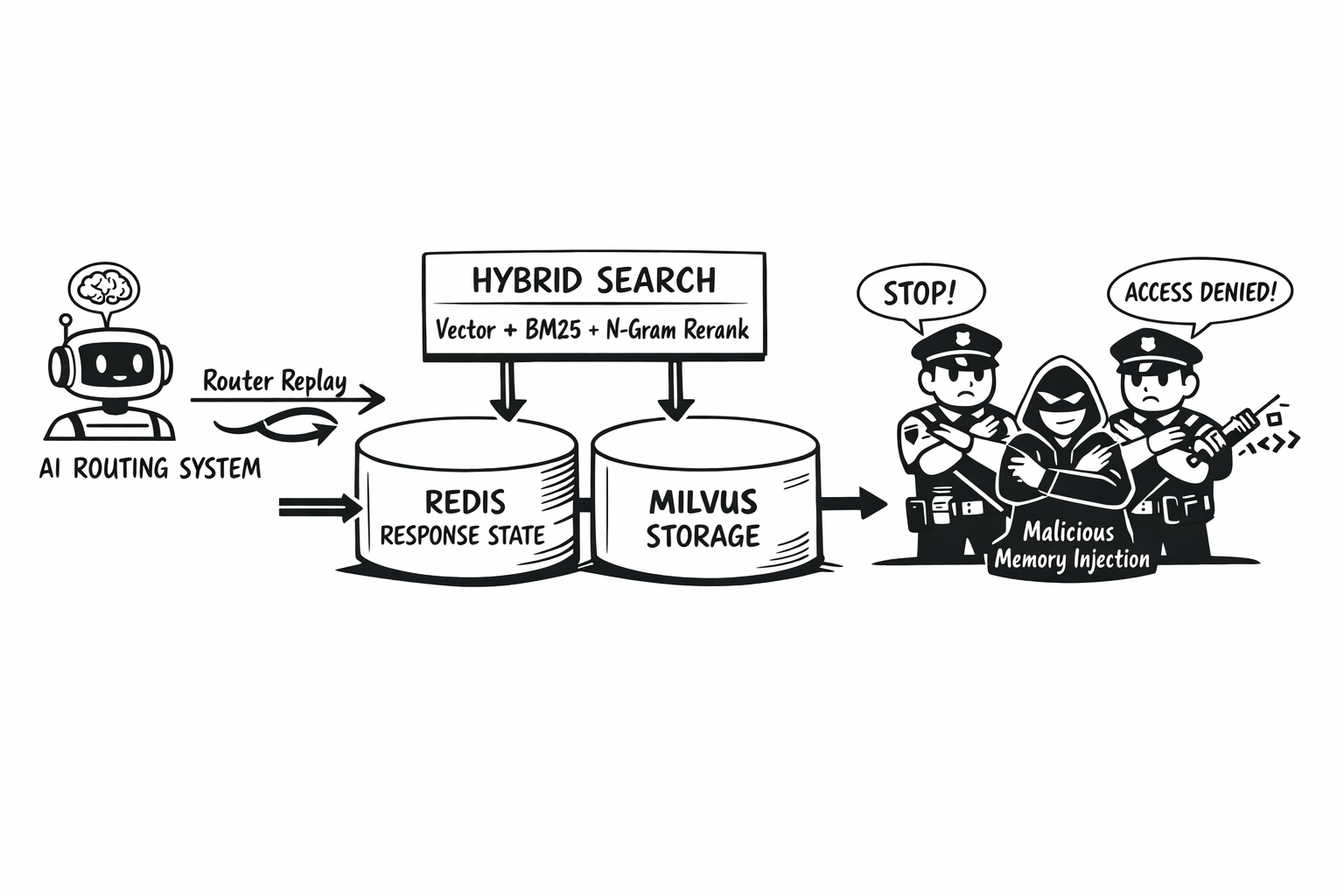
Just as important, the memory layer became more trustworthy:
- MINJA defenses to reduce memory injection attacks
- Response-level jailbreak gating before memory storage
- Cross-model cache sharing and improved cache update paths
- Demand RAG and vector-store oriented ingestion workflows
Athena turns routing from a stateless decision point into a system that can remember, retrieve, verify, and replay.
5. Signals Get Richer, Faster, and Safer
Iris introduced the Signal-Decision architecture. Athena significantly expands it.
At a high level, the signal layer got broader in three directions: it understands more about the request, it supports more deterministic and semantic matching paths, and it exposes more of that intelligence as reusable named signals inside the routing system.
| Signal surface | What Athena adds | Why it matters |
|---|---|---|
| Core request understanding | Language, latency, context, and complexity-aware signals, including few-shot complexity variants | The router can reason about more than topic alone when evaluating decisions. |
| Control and routing context | Modality and authz signals | Routing can branch on media intent and access constraints earlier in the pipeline. |
| Feedback loop | Feedback and preference classifiers | User-side signals become first-class routing inputs instead of side metadata. |
| Semantic matching path | Multimodal embedding support, soft embedding rules, and HNSW acceleration | Semantic matching becomes broader and faster, especially as retrieval surfaces grow. |
| Deterministic fast path | BM25, n-gram fuzzy matching, and regex for keyword routing | The auditable rule path stays interpretable, but becomes much less brittle in real traffic. |
| Runtime confidence layer | Dynamic confidence scoring across signal evaluation | Decisions can use richer signal quality instead of only binary matches. |
Safety also moved closer to the main signal path instead of staying off to the side as plugin-only post-processing:
| Safety surface | What Athena adds | Why it matters |
|---|---|---|
| Jailbreak detection | Promoted into parallel signals, with both classifier-based and contrastive multi-turn detection | The router can catch both obvious single-turn attacks and gradual escalation across a conversation. |
| PII detection | Parallel signal handling plus expanded policy and reveal controls | Sensitive data handling becomes part of the same routing and enforcement layer. |
| Tool safety | Confidence-gated reranking for tool filtering | Tool-aware workflows can stay selective without hardcoding every edge case. |
| Hallucination handling | More flexible multi-level response handling | The system can warn, annotate, or surface response risk with more nuance. |
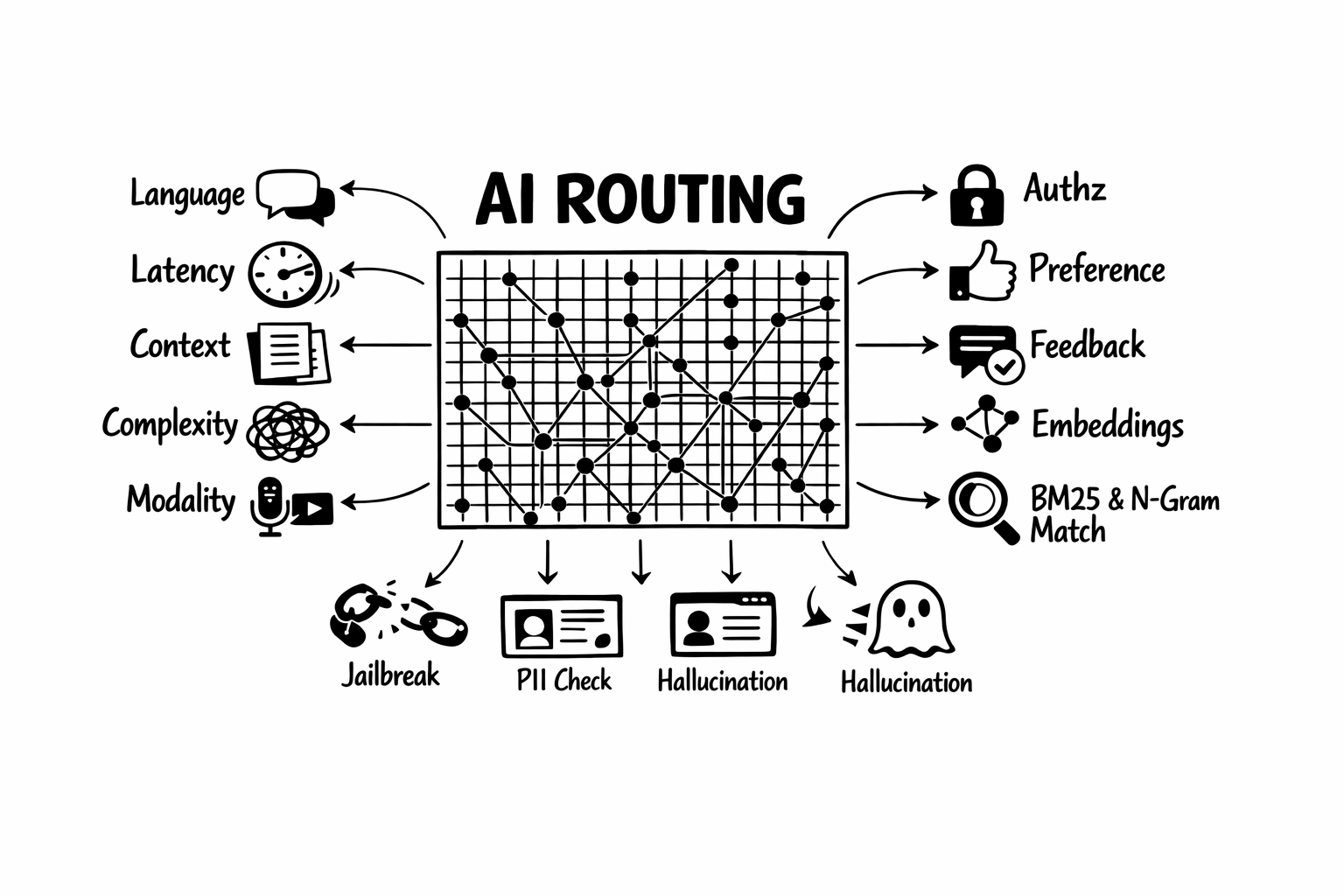
One important detail here is that keyword routing is no longer limited to exact literal matches. Athena adds a stronger keyword signal path with three complementary methods:
- BM25 for topic-style routing across larger keyword sets, where natural TF-IDF-style weighting helps surface the right deterministic rule
- n-gram matching for typo-tolerant routing, so near-miss inputs can still trigger the intended rule without falling back immediately to a heavier model path
- regex where teams need exact pattern control for compliance and structured detection
That matters because it upgrades one of the router's most interpretable primitives. The fast path stays auditable and deterministic, but it is much less brittle in real traffic. A query with noisy wording, partial overlap, or spelling mistakes no longer has to miss the keyword layer just because it is not a perfect string match.
Athena is not just broader. It is also faster. Signal parallelism, faster extraction paths, better embedding lookup behavior, and stronger keyword and safety paths all help the runtime scale without losing explainability.
6. NLP-Based Prompt Compression Becomes a First-Class Long-Context Primitive
Athena also introduces a new long-context runtime primitive: NLP-based prompt compression before signal extraction.
| Compression layer | What Athena does | Why it matters |
|---|---|---|
| Compression method | Uses TextRank, position weighting, TF-IDF, and novelty scoring | Long prompts can be reduced without adding another LLM hop. |
| Runtime placement | Compresses text only for signal extraction | The original request still goes to the serving model, so routing optimization does not rewrite the actual user prompt. |
| Safety preservation | Lets skip_signals keep jailbreak and PII on the original text | Sensitive classifiers can retain full-fidelity inspection where needed. |
| End-to-end path | Works with Envoy STREAMED body mode and fast JSON processing | The compression path translates into measurable production latency gains, not just a nicer architecture diagram. |
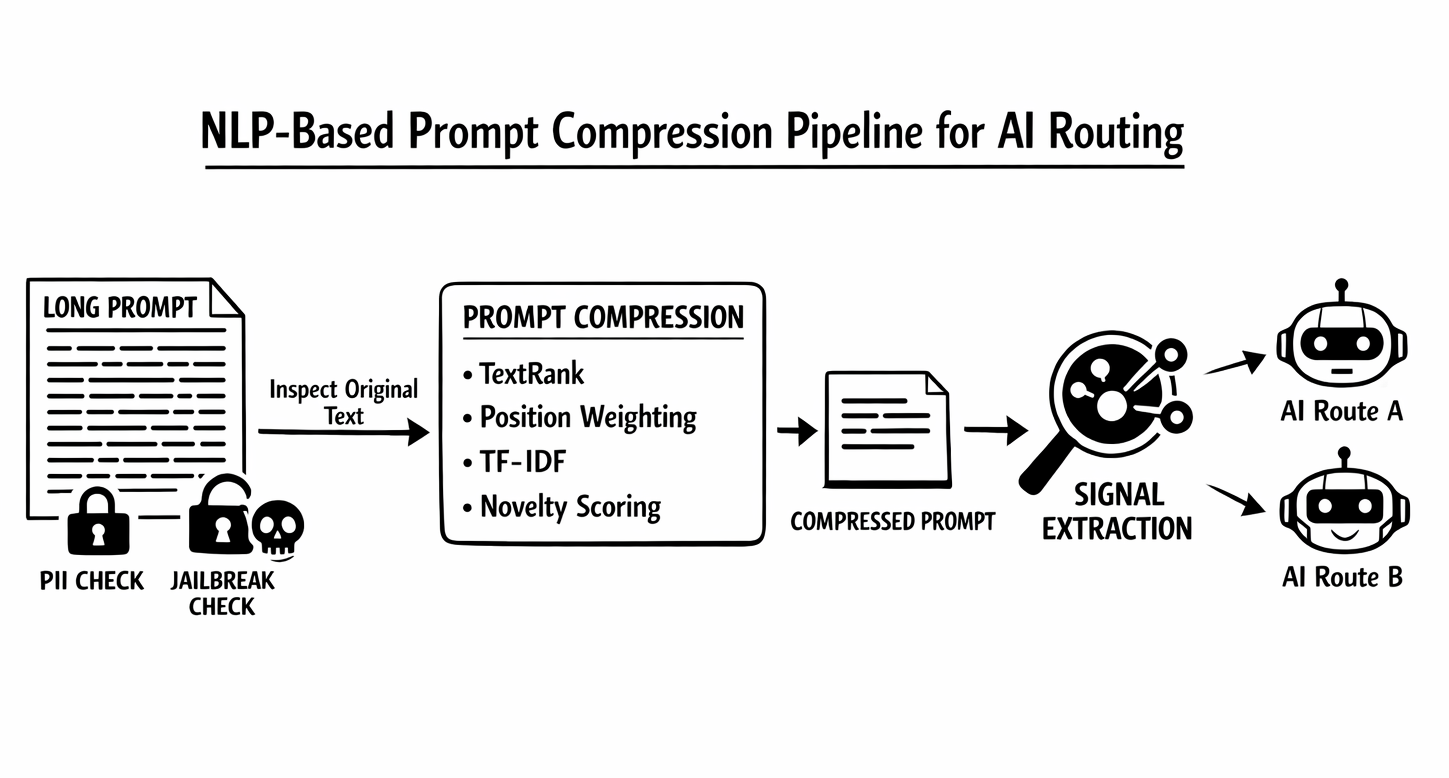
Instead of sending the full prompt through every signal classifier, Athena can now compress long prompts before signal extraction using this NLP-only pipeline. The compressed text is used only for signal extraction. The original prompt still goes upstream to the actual serving model, and signals that need full-fidelity input, such as jailbreak and PII by default, can keep reading the original uncompressed text through skip_signals.
This also ties into the runtime work around Envoy STREAMED body mode. In the repo's MI300X buffered-versus-streamed benchmark, the STREAMED path combines fast JSON processing, semi-streaming chunk delivery, and prompt compression to reduce end-to-end latency from 143 ms to 103 ms at ~16K tokens, while jailbreak signal extraction drops from 127 ms to 10 ms when the prompt is compressed from 16K to 512 tokens for the signal path.
The important point is that this is not an LLM summarizer bolted onto the side. It is a deterministic NLP pipeline inserted directly into the signal path, making long-context classification materially cheaper without obscuring how the router reached its decision.
7. Programmable Neural-Symbolic Configuration Language
Another defining theme of Athena is that routing policy becomes a real language, not just a pile of YAML fragments. In the project white paper, we describe this as a Programmable Neural-Symbolic Configuration Language: a typed configuration language that acts as the instruction set for the routing inference engine, combining neural signal extraction with symbolic decision evaluation.
That framing is important because it changes what “routing configuration” means. Instead of treating router setup as hand-edited infrastructure YAML, Athena moves it toward a program synthesis problem: given a natural-language routing specification, generate a valid routing program. The paper makes this point explicitly, arguing that the language's functional completeness enables LLM-based coding agents to synthesize routing policies from natural-language specifications.
Athena lands the practical foundations of that idea:
- a full DSL compiler
- a visual builder
- richer dashboard CRUD flows for signals and decisions
- better convergence across config surfaces
- stronger deploy-time translation paths for Kubernetes-oriented environments
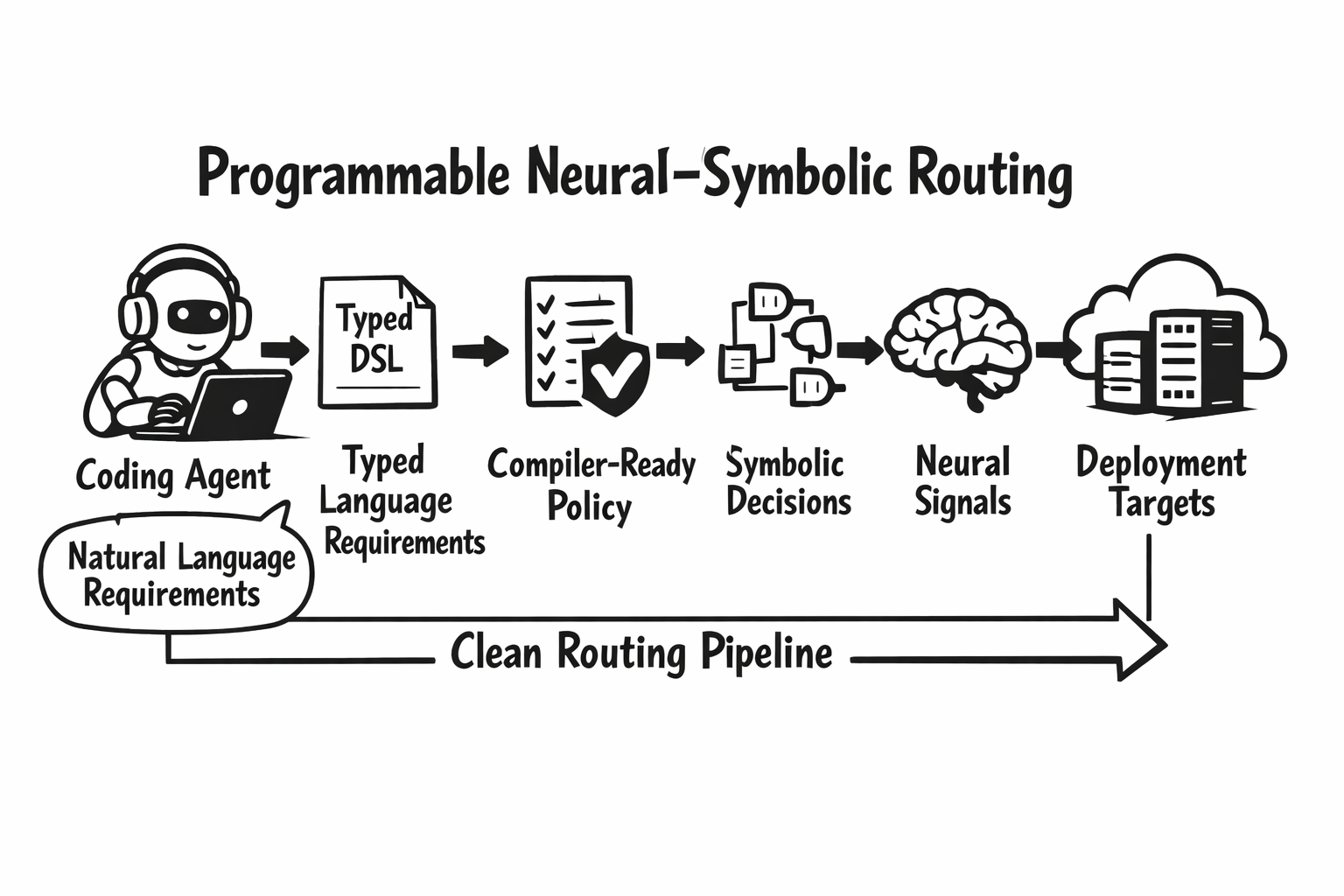
This closes a long-standing gap between:
- runtime config used by the router
- authoring surfaces exposed in the dashboard
- CLI-driven config workflows
- deploy-time representations in Kubernetes-oriented environments
Athena also includes fixes that make this language-driven authoring loop more reliable in practice, including improved config reload behavior and apiserver classification service refresh after deploy reload.
In short, Athena makes semantic routing easier to program, inspect, and evolve, not just execute. More importantly, it makes routing authoring legible to both humans and coding agents: the router becomes something you can compile, validate, round-trip, and increasingly ask an agent to write.
8. Zero-Config Onboarding Changes the First-Run Experience
Athena also delivers one of the most important UX improvements in the project so far: installation and first-run setup now form one continuous flow. You no longer need to start from a predefined config just to get the system running.
On macOS and Linux, the new one-line installer can now take users from install to dashboard with almost no manual setup:
curl -fsSL https://vllm-semantic-router.com/install.sh | bashThat installer detects Python, installs vllm-sr into an isolated local environment, writes a launcher to ~/.local/bin/vllm-sr, prepares Docker or Podman for local serving unless you opt out, and then runs the first vllm-sr serve automatically. When possible it also opens the dashboard, and on remote machines it prints access and SSH tunnel hints instead of failing silently.
After that first install, or any time users later run:
vllm-sr servefrom an empty directory, Semantic Router can:
- bootstrap a minimal workspace automatically
- create
.vllm-sr/router-defaults.yamlbehind the scenes - launch the dashboard in setup mode
- guide the user through first model setup and a routing starter choice
- write the generated
config.yamlonly after activation
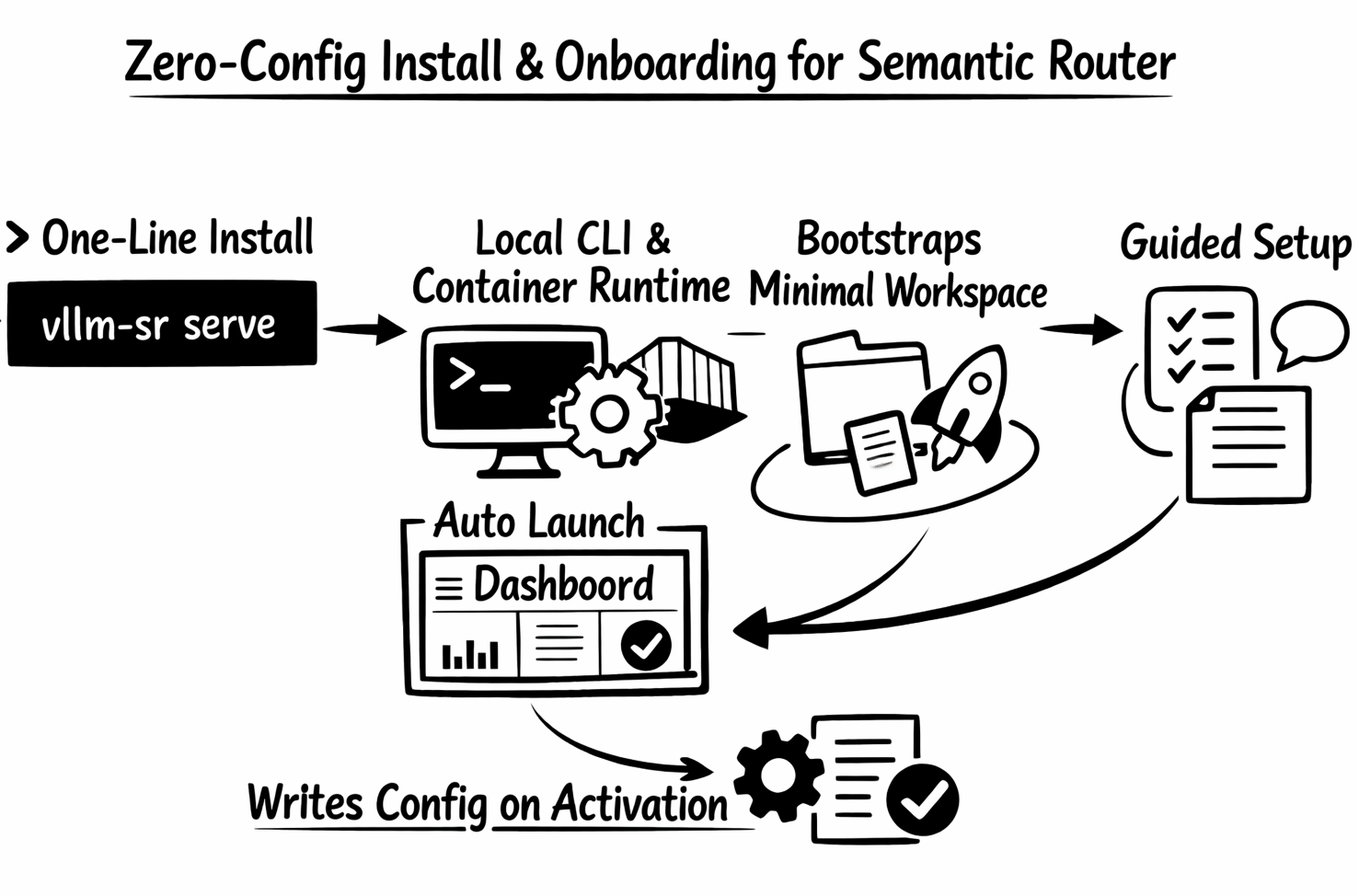
This is a major shift from a YAML-first onboarding story to a dashboard-first first-run experience. YAML authoring is still there for advanced users, but vllm-sr init is now optional rather than the price of entry. The installer also adds a cleaner operating model around that first run: users can choose CLI-only mode, skip auto-launch, pin the runtime, or force the first launch onto the AMD path with --platform amd.
That changes the product in a practical way: the shortest path from install to a working router becomes install, auto-launch, open dashboard, configure one model, activate.
9. The Dashboard Becomes a Real System Brain
Athena brings a large step forward in dashboard UX.
Highlights from this cycle include:
- Topology visualization with test-query support
- Router Replay visualization
- Evaluation API and dashboard evaluation surfaces
- Monitoring and observability improvements
- Reasoning-aware playground support
- Readonly dashboard mode for public beta and demo deployments
- MCP tools support in the dashboard
- broad layout, mobile, landing-page, manager, and monitoring refinements
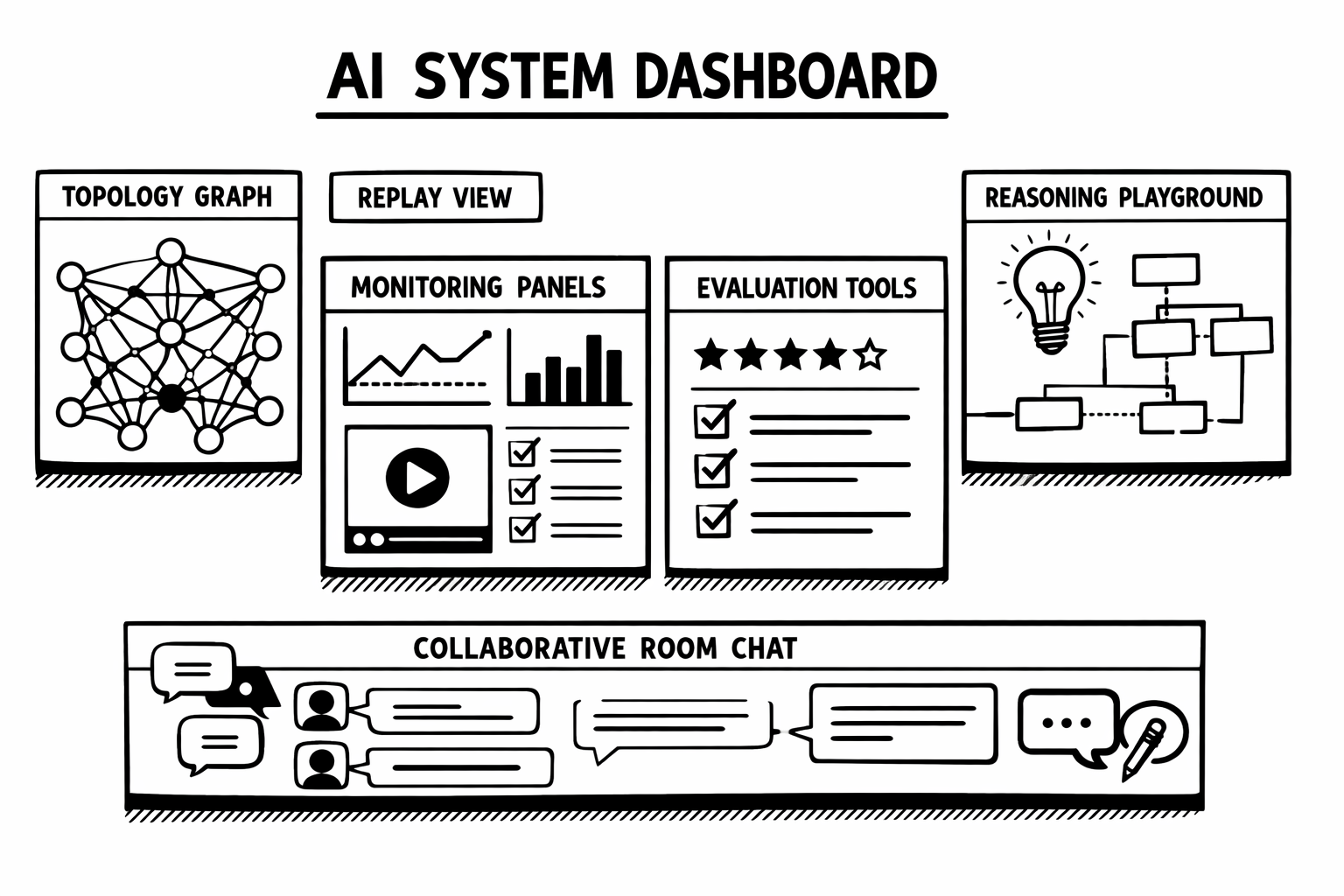
The result is that users can now do much more than tweak YAML and inspect logs. They can interactively observe, debug, evaluate, and demonstrate system behavior from the dashboard itself.
10. AMD ROCm Becomes a First-Class vllm-sr Deployment Path
Athena turns the AMD path into a canonical vllm-sr deployment flow, not a side experiment. The project now has a real ROCm edition of the vllm-sr image, an AMD deployment playbook, and a clear CLI surface for running the router on AMD GPUs with ONNX acceleration.
The local image-first flow is now explicit:
vllm-sr serve --platform amdThat --platform amd flag is more than branding. In the repo's AMD path, it selects ROCm image defaults, passes the AMD platform through the container runtime, enables GPU-first config defaults by flipping use_cpu flags to false unless explicitly disabled, and mounts the expected ROCm devices such as /dev/kfd and /dev/dri when they are present on the host.
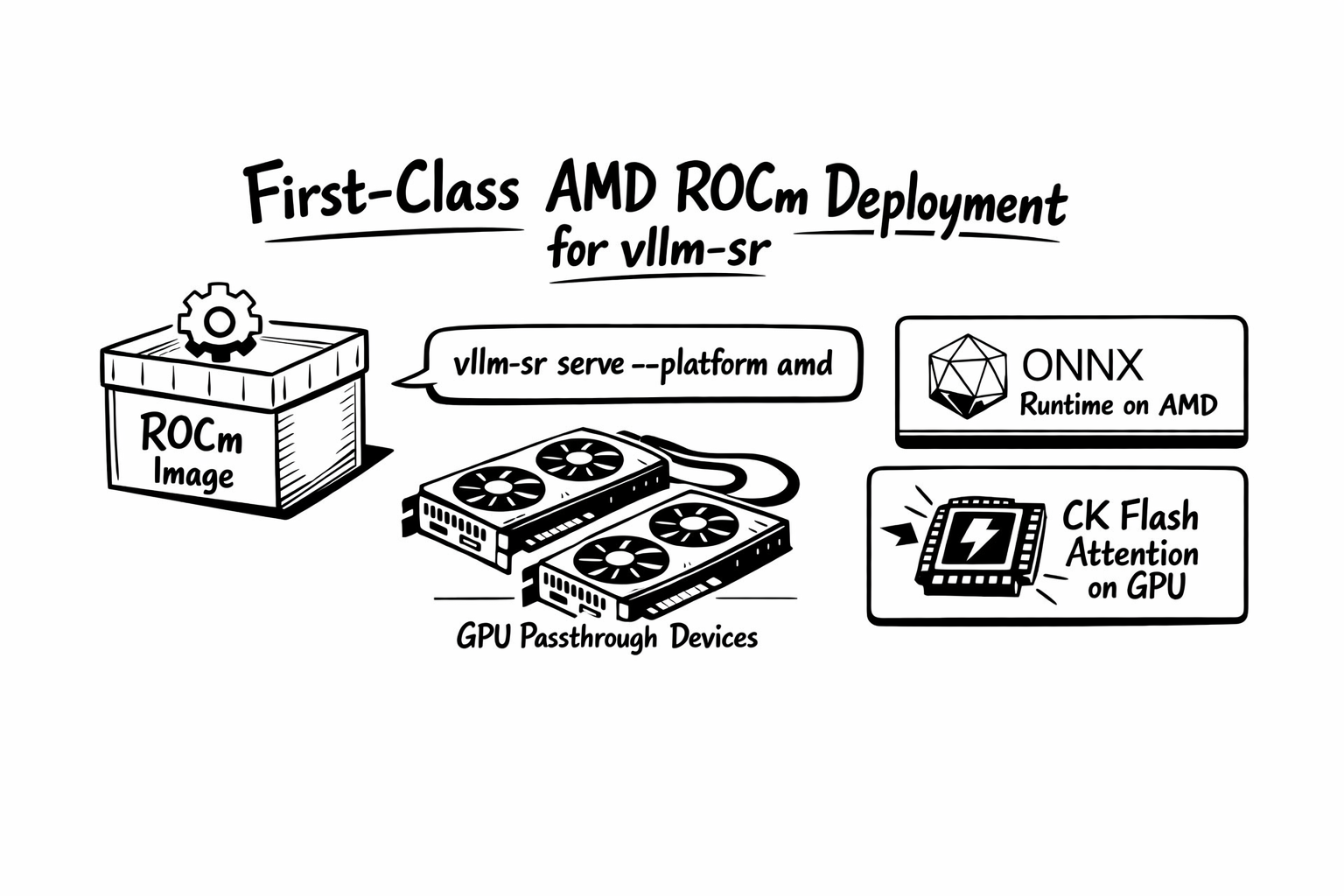
Under the hood, the ROCm image is also aligned with the ONNX runtime story described earlier in this post. The vllm-sr ROCm image builds the ONNX-backed router, installs ROCm ONNX Runtime, and can load the AMD CK Flash Attention custom op. In practical terms, that means Athena can run FA + GPU on AMD ROCm through the standard vllm-sr serve --platform amd path instead of forcing users into a separate custom stack.
The project also now ships a clearer reference AMD profile for real deployments, including alias-based routing against a ROCm vLLM backend. So the deployment story is no longer just “Semantic Router can, in theory, run on AMD.” It is that the project now has an end-to-end AMD path with a dedicated image, documented serve flow, GPU passthrough behavior, and ONNX + Flash Attention acceleration built into the intended operator experience.
11. Athena Was Also a Research and Model Systems Cycle
Athena is not only a product release. It is also a research and model-systems cycle. During this period, the project:
- published the Signal Driven Decision Routing for Mixture-of-Modality Models white paper
- advanced multimodal and modality-aware model training, including cross-modal embedding work and mmBERT-based classifier and modality-router training
- pushed longer-context model acceleration into the core stack through CK Flash Attention, ONNX graph rewriting, and ROCm-oriented inference paths
- tightened the bridge between model research, training artifacts, and deployable runtime surfaces
That combination matters. Semantic routing only becomes durable infrastructure when research ideas, model training, and production systems work move together. Athena is the clearest expression of that philosophy so far.
Looking Ahead: Beyond Athena
Athena operationalizes strategic routing. The next phase is about closing the loop:
- a training coding agent that can write and revise the routing DSL from natural-language requirements
- a self-learning loop that uses reverse signals and routing outcomes to iteratively improve signal and decision rules
- deeper multi-turn memory and agentic tool workflows
- more production-grade operator and system-brain automation
- broader multimodal and tool-aware safety coverage
- continued convergence between research prototypes and deployable runtime surfaces
Acknowledgments
From v0.1.0 on January 5, 2026 to main on March 9, 2026, the Athena cycle brought 304 commits from 43 contributors. Thank you to everyone who pushed code, reviewed PRs, improved docs, expanded tests, trained models, and helped turn semantic routing into a more complete system.
We are especially grateful to the maintainers and contributors driving the project across runtime, dashboard, infrastructure, evaluation, and research directions.
We also want to thank Red Hat, IBM, AMD, NVIDIA, DaoCloud, and the broader open-source community for their collaboration, engineering support, feedback, and continued investment in open model systems. Athena is the result of a community that is moving fast without losing sight of architecture.
Get Started
Ready to try vLLM Semantic Router v0.2 Athena?
If you want to try the hosted experience before installing locally, visit play.vllm-semantic-router.com.
# macOS/Linux one-line installer
curl -fsSL https://vllm-semantic-router.com/install.sh | bashThis installs the CLI, prepares the local Docker or Podman runtime for vllm-sr serve, runs the first launch automatically, and opens the dashboard when possible.
If you prefer the manual PyPI flow, or if you are on Windows:
pip install vllm-sr
vllm-sr serveIf config.yaml does not exist yet, vllm-sr serve bootstraps a minimal setup config and starts the dashboard in setup mode. If you prefer a YAML-first workflow, you can still run vllm-sr init before vllm-sr serve.
For Kubernetes-oriented deployments:
helm install semantic-router oci://ghcr.io/vllm-project/charts/semantic-routerSee the latest docs and project resources:
- Documentation: vllm-semantic-router.com
- GitHub: vllm-project/semantic-router
- Models: Hugging Face
- Community: Join us on Slack in vLLM Slack
The bridge can now reason strategically. Welcome to Athena.